 InnoDB的插入缓冲和自适应哈希索引
InnoDB的插入缓冲和自适应哈希索引
作者:鱼仔
博客首页: codeease.top (opens new window)
公众号:神秘的鱼仔
# 前言
为了增加数据库的读能力,InnoDB设计了 Buffer Pool 缓冲池,将热点数据留在内存中,极大提高了数据库的读性能。除此之外,InnoDB还有一种叫做 Change Buffer的特性同样至关重要。
# 为什么需要 Change Buffer
相比于顺序读写,随机读写在操作系统上的性能是十分弱的。假设有下面一张表:
CREATE TABLE `food` (
`id` int NOT NULL,
`name` varchar(255) DEFAULT NULL,
`parent_id` int DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_name` (`name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
2
3
4
5
6
7
在上面这张表中定义了一个主键索引,又定义了一个二级索引 idx_name。
当往 food 表里插入数据的时候,数据页的存放按照主键 a 进行顺序存放。但是 idx_name 这个二级索引叶子节点的插入就不是顺序的了,而是需要离散地访问该索引页。前面讲到了,相比于顺序读写,随机读写在操作系统上的性能是十分弱的。
为了降低随机读写对性能的影响,InnoDB 引入了 Change Buffer。在 InnoDB1.0.x 版本之前,Change Buffer 只支持对插入数据的缓存,因此很多地方看到的是 Insert Buffer;后面的版本 Change Buffer 可以对 Insert、Delete、Update 都进行缓冲。
简单来讲,Change Buffer 是将写操作缓存到了 Change Buffer 中,在适当的时机和情况下写入磁盘。
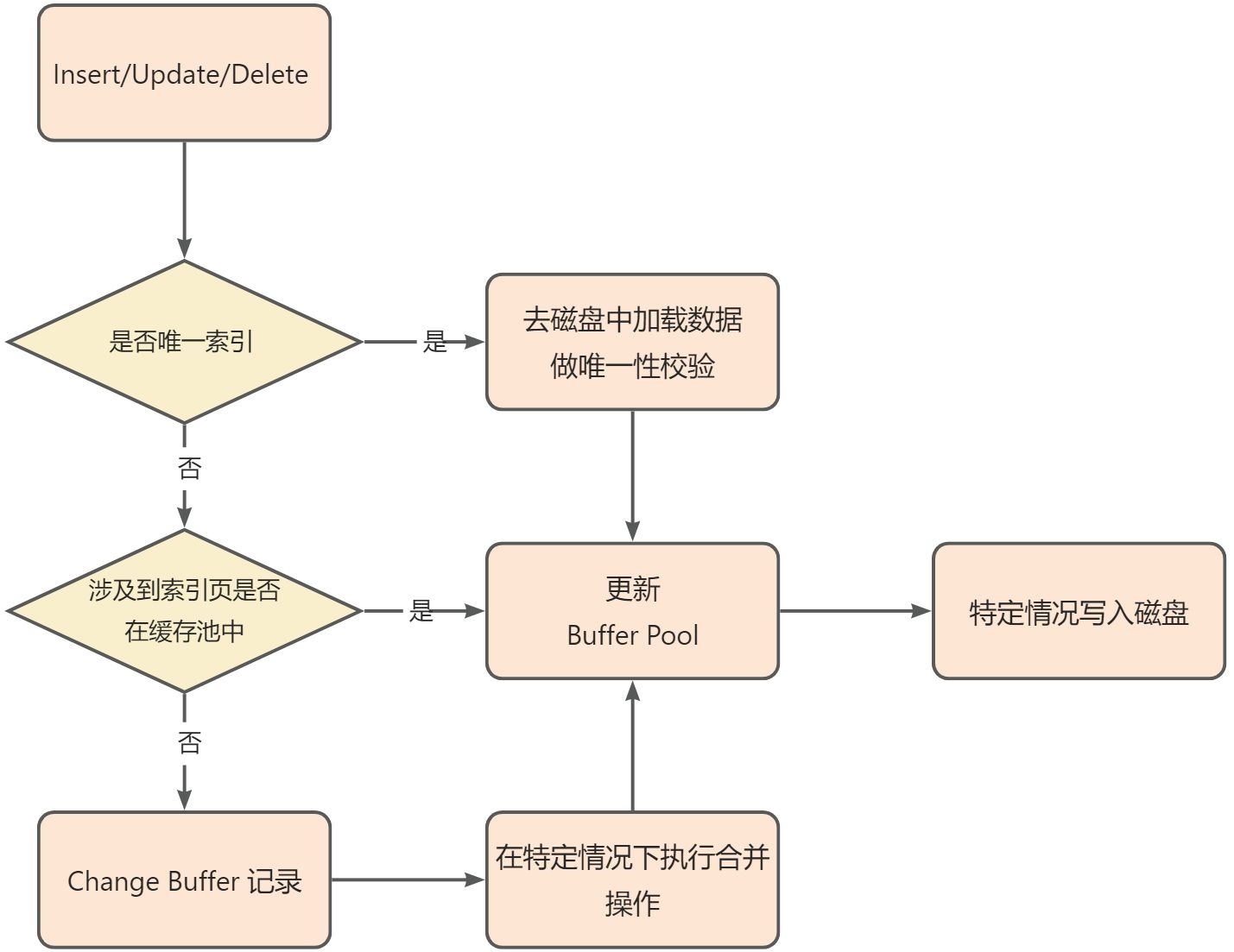
# Change Buffer是如何工作的
对于非唯一辅助索引的变更操作,并不是每次数据的变更都直接将数据插入到索引页中,而是通过下面这个流程来进行处理:
- 判断要变更的索引页是否在 Buffer Pool 中,如果在的话直接改索引页。
- 如果要变更的索引没在 Buffer Pool 中,将变更额外存储到 Change Buffer 对象中。
- 当有查询请求时,InnoDB会将变更和实际的数据进行 Merge 操作,保证数据一致性。
- 如果没有查询请求,InnoDB会按照特定的频率和情况将数据合并到磁盘中,将原本的多次写入合并为一次写入,极大提高非唯一辅助索引的插入性能。
Change Buffer 的合并操作主要在以下几个场景下触发
- 辅助索引被读取到Buffer Pool的时候:当一段查询操作将辅助索引加载到缓冲池的时候,Change Buffer 中对应的变更信息会进行一次合并。
- Change Buffer 达到一定占用空间之后:如果已使用的 Change Buffer 达到了一定占用空间,会直接进行一次合并操作。
- Master Thread 定期执行合并 Change Buffer 的操作。
# 为什么Change Buffer只适用非唯一索引
从上面的介绍中已经知道了 Change Buffer 只能用于非唯一辅助索引,但这是为什么呢?
主要的原因是如果这个索引是唯一索引,那就必须去做唯一性校验,因此不得不去磁盘中加载数据。如果此时再放到 Change Buffer 中反而多了一道无用的操作。
# Change Buffer 相关参数
change buffer 占用内存大小
show variables like 'innodb_change_buffer_max_size'
innodb_change_buffer_max_size 表示 change buffer 最大占用内存的大小,默认为25,表示占用缓冲池大小的25%。
查看 Change Buffer 情况
show engine innodb status
找到下面的结果:
-------------------------------------
INSERT BUFFER AND ADAPTIVE HASH INDEX
-------------------------------------
Ibuf: size 1, free list len 0, seg size 2, 0 merges
merged operations:
insert 0, delete mark 0, delete 0
discarded operations:
insert 0, delete mark 0, delete 0
2
3
4
5
6
7
8
因为这个数据库是我自己搭着玩的所以几乎没有数据,可以看一下里面的内容
表头还是沿用了历史的 INSERT BUFFER ,后面的 ADAPTIVE HASH INDEX 是自适应哈希索引的内容。
seg size:当前 Insert Buffer的大小2*16KB=32KB;
free list len:空闲列表的长度;
size :已经合并记录页的数量;
merges:合并的次数,也就是实际读取页的次数;
merged operations 中:
insert:insert buffer 大小
delete mark:delete buffer 大小
delete:purge buffer 大小
discarded operations 表示已经被丢弃的操作信息。比如缓存了一些对表的变更操作,但是这张表被删除了,就无需再做合并了。
# 自适应哈希索引
在上面查看 Change Buffer 情况的时候,可以看到自适应哈希索引的信息也被放在了一个模块上。
-------------------------------------
INSERT BUFFER AND ADAPTIVE HASH INDEX
-------------------------------------
Ibuf: size 1, free list len 0, seg size 2, 0 merges
merged operations:
insert 0, delete mark 0, delete 0
discarded operations:
insert 0, delete mark 0, delete 0
Hash table size 34679, node heap has 0 buffer(s)
Hash table size 34679, node heap has 0 buffer(s)
Hash table size 34679, node heap has 0 buffer(s)
Hash table size 34679, node heap has 0 buffer(s)
Hash table size 34679, node heap has 1 buffer(s)
Hash table size 34679, node heap has 1 buffer(s)
Hash table size 34679, node heap has 2 buffer(s)
Hash table size 34679, node heap has 5 buffer(s)
0.00 hash searches/s, 0.00 non-hash searches/s
---
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
自适应哈希索引是对B+树的一种优化,需要注意的是自适应哈希索引不需要手工去配置,完全由 InnoDB 引擎控制。
一般生产环境的数据量下,B+树的层级往往是在3到4层,意味着需要查询3到4次才能查到叶子节点。但是通过哈希索引只需要一次。
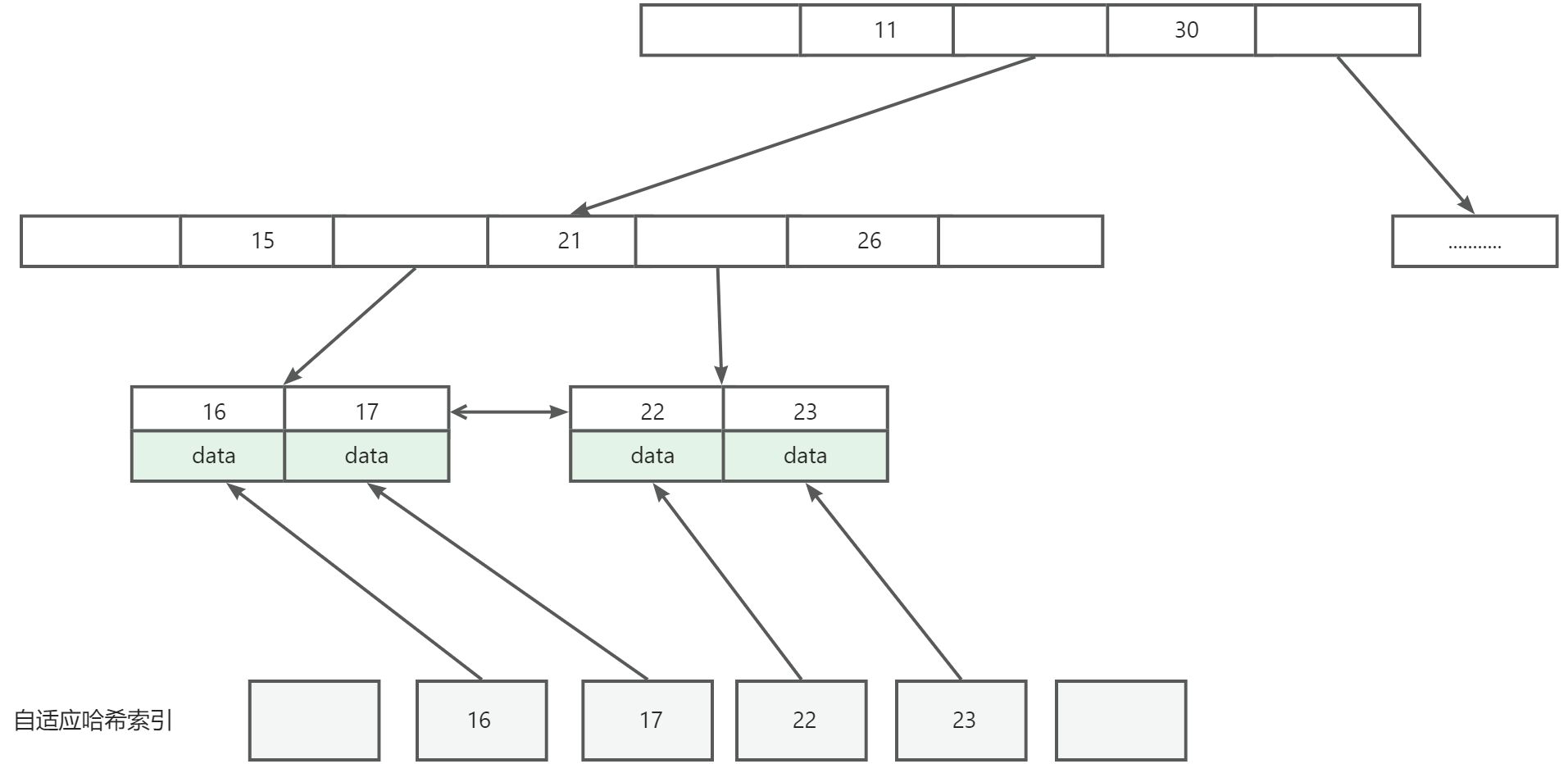
自适应哈希索引属于InnoDB层面的优化,无需开发人员手动介入。