 PostgreSQL表的继承及分区
PostgreSQL表的继承及分区
作者:鱼仔
博客首页: codeease.top (opens new window)
公众号:神秘的鱼仔
# 引言
你是一个后端程序员,你会在Java代码中去写一个父类,然后写一个子类继承父类,这是一种面向对象的思想。但如果和你说数据库中的表也能继承,这样的数据库你见过吗?本篇博客我们就来看看PGSQL表的继承和分区特性。
# 继承
# 案例
我们从一个实际的案例出发,父表是员工表 employees 存储通用信息,子表为经理表 managers 和开发者表 developers,并且经理表和开发者表都有自己的一些属性,这就比较符合面向对象的设计了。
# 创建表
然后第一步,创建父表,同时给父表添加索引,子表会继承父表的索引:
-- 创建父表:通用员工信息
CREATE TABLE employees (
id SERIAL PRIMARY KEY,
name VARCHAR(100) NOT NULL,
department VARCHAR(50),
salary DECIMAL(10, 2) CHECK (salary > 0)
);
-- 为父表添加索引(子表会继承)
CREATE INDEX idx_employees_dept ON employees(department);
2
3
4
5
6
7
8
9
10
接下来是第二步 创建子表,创建子表会用到一个关键字 INHERITS 表示继承
-- 创建经理子表:继承员工信息 + 团队规模
CREATE TABLE managers (
team_size INTEGER CHECK (team_size >= 0),
performance_rating VARCHAR(10)
) INHERITS (employees);
-- 创建开发者子表:继承员工信息 + 编程语言
CREATE TABLE developers (
programming_language VARCHAR(50) NOT NULL,
years_experience INTEGER DEFAULT 0
) INHERITS (employees);
2
3
4
5
6
7
8
9
10
11
和很多面向对象的编程语言一样,子表会继承父表的所有列,同时子表不能覆盖或修改父表的列定义。
# 插入数据
插入数据有几个规范:
插入到父表时,数据会只插入父表;插入到子表时,数据会同时插入子表和父表。
-- 插入到父表(只影响父表)
INSERT INTO employees (name, department, salary) VALUES ('Alice', 'HR', 8000.00);
-- 插入到经理子表(同时插入 managers 和 employees)
INSERT INTO managers (name, department, salary, team_size, performance_rating)
VALUES ('Bob', 'Engineering', 30000.00, 10, 'A');
-- 插入到开发者子表(同时插入 developers 和 employees)
INSERT INTO developers (name, department, salary, programming_language, years_experience)
VALUES ('Charlie', 'Engineering', 10000.00, 'Java', 5);
2
3
4
5
6
7
8
9
10
更新数据的特性和插入的特性是一样的。
# 查询数据
插入数据有几个注意点:
查询父表时,会返回父表的结构,数据是父表及所有子表的数据;如果只想查询父表就用ONLY关键字;
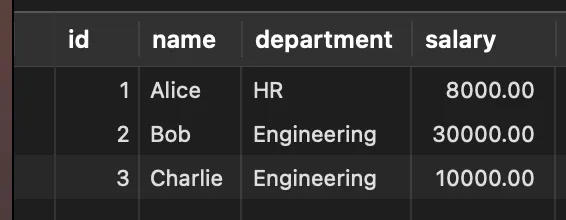
-- 查询所有员工
select * from employees;
2
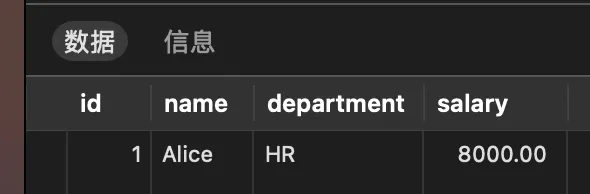
-- 只查询父表数据
SELECT * FROM ONLY employees;
2
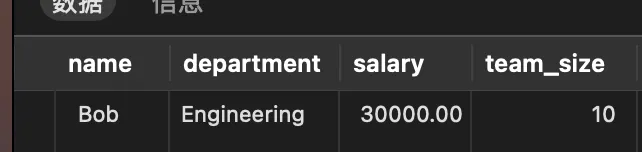
-- 查询经理(包括继承的列)
SELECT name, department, salary, team_size FROM managers;
2
# 核心特性总结
- 列继承:
- 子表自动继承父表的所有列(包括数据类型、默认值和 NOT NULL 约束)。
- 子表不能覆盖或修改父表的列定义(例如,不能更改数据类型),但可以添加自己的额外列。
- 子表的列名必须与父表不冲突。
- 约束继承:
- 子表继承父表的主键(PRIMARY KEY)、唯一约束(UNIQUE)、外键(FOREIGN KEY) 和 检查约束(CHECK)。
- 子表可以添加自己的约束,但继承的约束会应用于子表的数据。
- 注意:主键继承时,子表需要有自己的主键(不能直接使用父表的),否则会报错。
- 索引和触发器继承:
- 子表继承父表的索引(包括唯一索引和部分索引)。
- 子表继承父表的触发器(TRIGGER) 和 规则(RULE)。
- 这有助于维护一致性和性能。
- 查询继承表:
- 查询父表时,会返回父表的结构,数据是父表及所有子表的数据
- 要查询所有继承数据,使用 ONLY 关键字:SELECT * FROM ONLY parent_table;(只查父表)。
- 省略 ONLY 时:SELECT * FROM parent_table; 会自动包含所有子表的数据(类似于 UNION ALL)。
- 可以指定子表:SELECT * FROM child_table; 只返回子表数据(不包括父表)。
- 插入和更新:
- 插入到父表时,数据会只插入父表(不影响子表)。
- 插入到子表时,数据会同时插入子表和父表(PostgreSQL 会自动复制继承的列到父表)。
- 更新类似:更新子表会同步更新父表。
# 是否建议使用
从上面的例子大家应该就可以看出来了,如果使用了继承特性,表的结构会变得十分复杂。因此在业务上十分不推荐使用继承。官方在wiki中也提到了这样一个点。

早期的时候继承的特性更多被用于分区,因为PG 10 之前没有内置分区的功能,通过继承的方式就可以在子表中增加一个用于分区的字段,然后字段继承父表,变相实现了分区。
# 分区
# 什么是分区
分区是一种十分常用的数据库优化方案,目的是将大表拆分为小表,每个小表存储所有数据的一个子集,并且通过分区键区分表,可以提高查询性能,简化维护的难度,提高并行能力。分区适用于大规模的数据场景,尤其日志表、业务流水表或者时间序列表。
# PG支持的分区
PG支持下面几种类型的分区方式
- 范围分区(RANGE):按连续范围分区,常用于日期、数字(如按年/月分区日志表)。
- 列表分区(LIST):按离散值分区,如按地区或状态(如 'US'、'EU')。
- 哈希分区(HASH):按哈希值均匀分布,常用于无序数据(如用户 ID),确保负载均衡。
- 复合分区(PG 11+):支持多级分区(如先按年范围,再按月列表)。
- 子分区:分区可以进一步分区,形成树状结构。
# 分区案例
一个最常见的分区案例,日志表。如果不分区的话,日志表会越来越大,导致表大之后查询效率低,数据维护困难。
-- 创建主日志表:范围分区,按 log_date
CREATE TABLE logs (
id SERIAL,
log_date DATE NOT NULL,
message TEXT,
PRIMARY KEY (id, log_date) -- 主键必须包含分区键
) PARTITION BY RANGE (log_date);
2
3
4
5
6
7
第一步是创建日志主表,选择使用 log_date 作为分区键
-- 添加 2023 年分区
CREATE TABLE logs_2023 PARTITION OF logs
FOR VALUES FROM ('2023-01-01') TO ('2024-01-01');
-- 添加 2024 年分区
CREATE TABLE logs_2024 PARTITION OF logs
FOR VALUES FROM ('2024-01-01') TO ('2025-01-01');
-- 添加默认分区,未匹配到的数据默认进入这个分区
CREATE TABLE logs_default PARTITION OF logs DEFAULT;
2
3
4
5
6
7
8
9
10
添加三个分区,前两个指定了范围分区涉及到的范围,如果没有匹配到前两个分区,数据就会进入到默认分区中。
-- 插入数据
INSERT INTO logs (log_date, message) VALUES ('2023-06-15', '登陆失败');
INSERT INTO logs (log_date, message) VALUES ('2024-03-20', '登陆成功');
INSERT INTO logs (log_date, message) VALUES ('2025-01-10', '登陆失败');
2
3
4
现在当插入数据的时候,数据就会自动路由到对应的分区。
查询的方式和普通查询是一样的,只要通过分区键进行筛选,PG就会自动剪枝,只查需要的分支,大幅提升性能:
SELECT * FROM logs WHERE log_date > '2024-01-01';
我们可以通过explain来看一下上面这行命令执行计划:
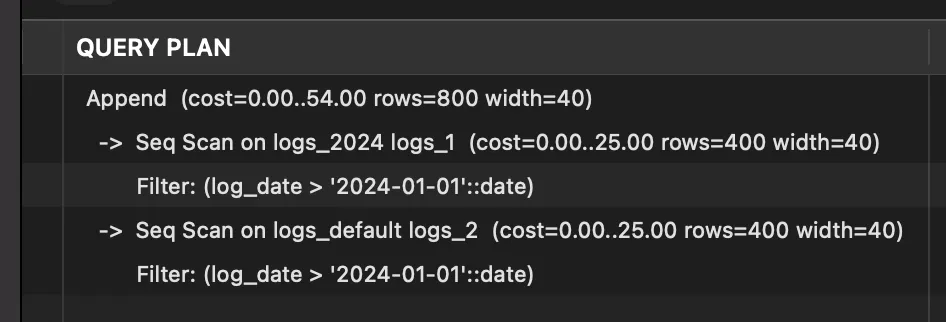
可以看到它直接跳过了2023的这个分区。
在查询时也可以直接指定对应的分区写SQL
SELECT * FROM logs_2024;
删除分区
删除分区最简单的方法是直接删除,就和删除一张表一样
DROP TABLE logs_2023;
但很多时候我们需要对表进行保留,可能用于迁移数据或者备份数据,就可以先将分区表独立出来,命令为:
ALTER TABLE logs DETACH PARTITION logs_2023;
这种方式会立即将logs_2023这个分区表独立出来,但是这个操作会阻塞所有对父表和分区的读写操作,这就可以使用下面这种方式:
ALTER TABLE logs DETACH PARTITION logs_2023 CONCURRENTLY;
这样就会以非阻塞的方式分离分区了,在生产环境中几乎无感知。
# PG分区的特点
根据上面的案例,对PG分区的特点做个总结。
# 分区类型:
- 范围分区(RANGE):按连续范围分区,常用于日期、数字(如按年/月分区日志表)。
- 列表分区(LIST):按离散值分区,如按地区或状态(如 'US'、'EU')。
- 哈希分区(HASH):按哈希值均匀分布,常用于无序数据(如用户 ID),确保负载均衡。
- 复合分区:支持多级分区(如先按年范围,再按月列表)。
- 子分区:分区可以进一步分区,形成树状结构。
# 分区键(Partition Key):
- 必须是表的一个或多个列(表达式不支持)。
- 每个分区通过边界定义(VALUES FROM/TO 或 VALUES IN)指定数据范围。
- 默认分区(DEFAULT):捕获不匹配任何分区的行。
# 约束和继承:
- 分区表自动继承父表的列、约束、索引和触发器。
- 每个分区有隐式 CHECK 约束,确保数据路由正确。
- 主键/唯一约束必须包含分区键(否则跨分区唯一性无法保证)。
# 查询分区表:
- 查询父表时,PostgreSQL 使用分区剪枝(Partition Pruning)自动排除无关分区,提高性能。
- 使用 ONLY:SELECT * FROM ONLY parent_table; 只查父表(分区表无数据)。
- 跨分区查询支持并行执行。
# 插入、更新和删除:
- 插入时,数据自动路由到匹配的分区(基于分区键)。
- 更新:如果更新分区键,可能导致行移动到其他分区。
- 删除分区:使用 DROP TABLE partition_name; 快速移除整个分区,而非逐行删除。
- 附加/分离分区:ALTER TABLE parent_table ATTACH PARTITION child_table FOR VALUES ...; 或 DETACH。
# 和MySQL分区的区别
MySQL8也是支持分区的,但是MySQL的分区是存储引擎级别的支持;分区是表的一个属性,数据分布在同一表文件中。PG在分区剪枝以及并行查询的优化上要比MySQL更好,如果系统查询复杂,数据集很大,PG的效果会比MySQL好很多。
# 参考链接
https://www.postgresql.org/docs/current/ddl-partitioning.html (opens new window)
https://www.postgresql.org/docs/current/ddl-inherit.html (opens new window)
https://wiki.postgresql.org/wiki/Don't_Do_This#Don.27t_use_table_inheritance (opens new window)