 如何在自己的项目中引入ElasticSearch搜索引擎?
如何在自己的项目中引入ElasticSearch搜索引擎?
作者:鱼仔
博客首页: codeease.top (opens new window)
公众号:神秘的鱼仔
# (一)介绍
在大多数系统中,都需要支持搜索的功能,以简单博客系统为例,虽然说Mysql也可以通过模糊查询匹配到对应的数据,但是效率实在太低。这个时候就需要拿出分布式搜索引擎ElasticSearch了。本博客重点在于ES的集成使用,因此前端采用最简单的方式呈现,大家只需要关注后端逻辑即可。(本博客基于ES7.6.1,和ES6.X版本有较大差异)
# (二)项目搭建
# 2.1 依赖引入
依赖主要就是web、es以及thymleaf相关:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.76</version>
</dependency>
<!--thymleaf相关-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-thymeleaf</artifactId>
</dependency>
<dependency>
<groupId>org.thymeleaf</groupId>
<artifactId>thymeleaf-spring5</artifactId>
</dependency>
<dependency>
<groupId>org.thymeleaf.extras</groupId>
<artifactId>thymeleaf-extras-java8time</artifactId>
</dependency>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
# 2.2 编写ES的配置类
编写ES的配置类,编写连接信息,之后直接通过Autowired连接即可:
@Configuration
public class ElasticSearchConfig {
@Bean
public RestHighLevelClient restHighLevelClient(){
RestHighLevelClient client=new RestHighLevelClient(
RestClient.builder(
new HttpHost("192.168.78.128",9200,"http")
)
);
return client;
}
}
2
3
4
5
6
7
8
9
10
11
12
# 2.3 编写Blog实体类
编写一个类用来存储要存储的数据,我这里为了演示只在es中插入标题和作者的信息
@Data
@AllArgsConstructor
public class BlogDO {
private String title;
private String author;
}
2
3
4
5
6
# 2.4 准备controller和service
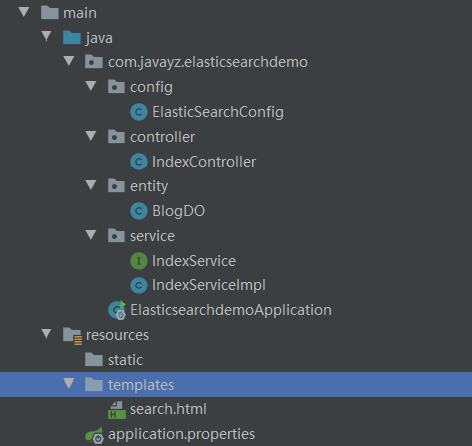
最后新建一个IndexController和IndexService以及IndexServiceImpl,接下来会使用。最终的目录结构如下:
# (三)数据准备
要做数据的搜索,首先第一步就是数据的导入。在真实的业务场景中,数据的导入有很多方式。一种是当新增数据时在代码逻辑中做增量的导入操作,或者是由数仓团队负责数据的增量导入。我接触到的业务中,后端程序员不需要去关注导入的操作,这个步骤是数仓团队做的。
在我们个人的博客系统中,可以在新增博客后立刻同步数据到ES,也可以先通过消息中间件发送一条消息,消费者定期去读取消息新增数据。
这里演示就直接导入了:
@Controller
public class IndexController {
@Autowired
private IndexService indexService;
@ResponseBody
@GetMapping("/prepareData")
public String prepareData(){
String result=indexService.prepareData();
return result;
}
}
2
3
4
5
6
7
8
9
10
11
具体的service实现如下:
@Service
public class IndexServiceImpl implements IndexService {
@Autowired
private RestHighLevelClient restHighLevelClient;
@Override
public String prepareData() {
List<BlogDO> blogDOS = new ArrayList<>();
blogDOS.add(new BlogDO("ElasticSearch究竟是个什么东西", "Java鱼仔"));
blogDOS.add(new BlogDO("SpringBoot+SpringSecurity实现基于真实数据的授权认证", "Java鱼仔"));
blogDOS.add(new BlogDO("Dubbo两小时快速上手教程(直接代码、Spring、SpringBoot)", "Java鱼仔"));
blogDOS.add(new BlogDO("浅析五种最常用的Java加密算法", "Java鱼仔"));
blogDOS.add(new BlogDO("Java程序员需要知道的操作系统知识汇总", "Java鱼仔"));
blogDOS.add(new BlogDO("一步步教你如何在SpringBoot项目中引入支付功能", "Java鱼仔"));
blogDOS.add(new BlogDO("Zookeeper实现分布式锁的原理是什么?", "Java鱼仔"));
blogDOS.add(new BlogDO("一个成熟的Java项目如何优雅地处理异常", "Java鱼仔"));
blogDOS.add(new BlogDO("基于SpringBoot实现文件的上传下载", "Java鱼仔"));
blogDOS.add(new BlogDO("如何用Java写一个规范的http接口?", "Java鱼仔"));
BulkRequest bulkRequest = new BulkRequest();
bulkRequest.timeout("10s");
blogDOS.stream().forEach(x -> {
bulkRequest.add(new IndexRequest("blog_index").source(JSON.toJSONString(x), XContentType.JSON));
});
BulkResponse responses=null;
try {
responses = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);
} catch (IOException e) {
e.printStackTrace();
}
return String.valueOf(responses.status());
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
我选取了自己的几篇博客文章,多执行几次接口,保证ES中有几十条数据供测试使用即可。
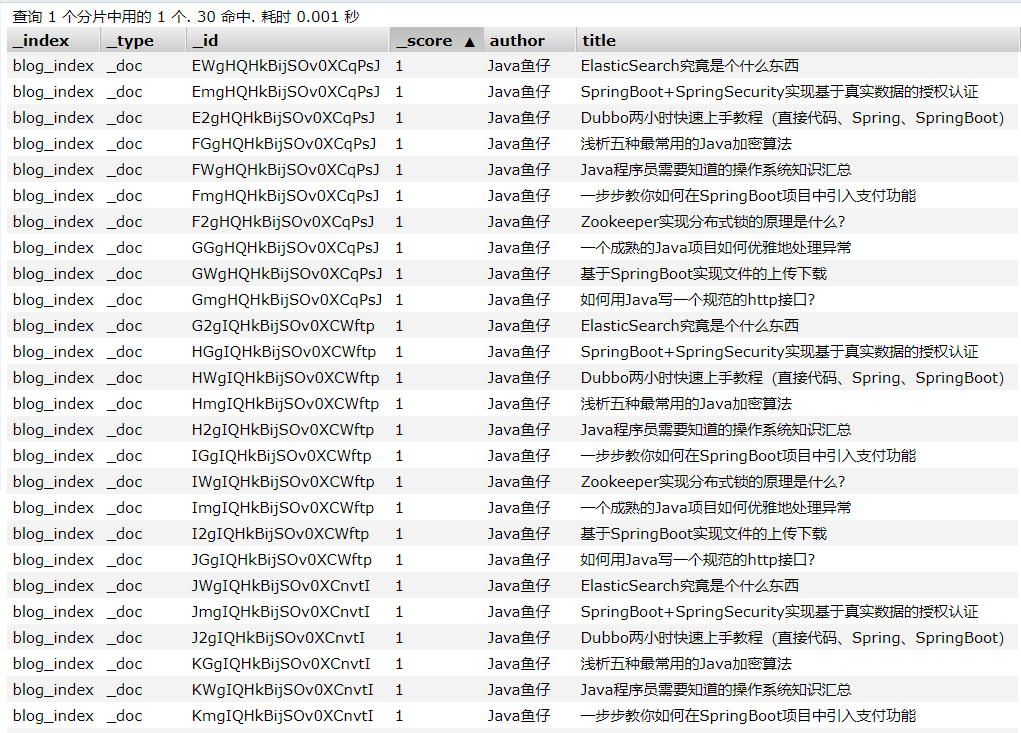
# (四)博客搜索
接下来就是搜索的过程了,搜索的逻辑其实比较简单,具体的代码就按照上一篇博客中的方式来编写,在真实业务场景中,每个公司可能会有自己的封装搜索方法:
IndexController中增加一个方法:
@GetMapping("/search")
public String search(@RequestParam("keywords")String keywords, @RequestParam("pageNum")String pageNum, @RequestParam("pageSize")String pageSize, Model model){
List<Map<String,Object>> list=indexService.searchByKeywords(keywords,pageNum,pageSize);
model.addAttribute("datas",list);
return "search";
}
2
3
4
5
6
具体实现类中增加方法:
@Override
public List<Map<String, Object>> searchByKeywords(String keywords, String pageNum, String pageSize) {
return this.searchData(keywords,Integer.parseInt(pageNum),Integer.parseInt(pageSize));
}
public List<Map<String,Object>> searchData(String keywords, int pageNum, int pageSize){
if (pageNum<1){
pageNum=1;
}
//生成搜索对象
SearchRequest request = new SearchRequest("blog_index");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//设置分页参数
searchSourceBuilder.from(pageNum);
searchSourceBuilder.size(pageSize);
//设置搜索的字段
MatchQueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("title", keywords);
searchSourceBuilder.query(matchQueryBuilder);
searchSourceBuilder.timeout(new TimeValue(10, TimeUnit.SECONDS));
request.source(searchSourceBuilder);
SearchResponse search=null;
try {
search = restHighLevelClient.search(request, RequestOptions.DEFAULT);
} catch (IOException e) {
e.printStackTrace();
}
//将结果返回
List<Map<String,Object>> result=new ArrayList();
SearchHit[] hits = search.getHits().getHits();
for (SearchHit searchHit:hits){
result.add(searchHit.getSourceAsMap());
}
return result;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
简单写一个前端页面
<!DOCTYPE html>
<html xmlns:th="http://www.thymeleaf.org"><!--引入thymeleaf-->
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<div>
<div th:each="datas:${datas}">
<span th:text="${datas.author}"/>
<span th:utext="${datas.title}"/>
<hr/>
</div>
</div>
</body>
</html>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
跑起来看一下,访问
http://localhost:8080/search?keywords=Java&pageNum=1&pageSize=10
在链接中,我关键词填了Java,pageNum是1,每页展示10行,可以看到和Java相关的数据就被查出来了。

# (五)实现高亮查询
在百度搜索Java时,可以看到查询出来的Java被高亮显示了,之前在讲ES语法的时候,我们也知道了ES支持高亮查询,下面就通过代码来实现。
稍微修改一下搜索的代码,增加高亮配置,在返回值中用高亮字符串替换原来的字符串。
public List<Map<String,Object>> searchHighLightData(String keywords, int pageNum, int pageSize){
if (pageNum<1){
pageNum=1;
}
SearchRequest request = new SearchRequest("blog_index");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.from(pageNum);
searchSourceBuilder.size(pageSize);
//高亮构造器
HighlightBuilder highlightBuilder=new HighlightBuilder();
//高亮查询字段
highlightBuilder.field("title");
//是否将所有匹配到的字段高亮显示,false表示只显示一个
highlightBuilder.requireFieldMatch(false);
//高亮的标签
highlightBuilder.preTags("<span style='color:red'>");
highlightBuilder.postTags("</span>");
searchSourceBuilder.highlighter(highlightBuilder);
MatchQueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("title", keywords);
searchSourceBuilder.query(matchQueryBuilder);
searchSourceBuilder.timeout(new TimeValue(10, TimeUnit.SECONDS));
request.source(searchSourceBuilder);
SearchResponse search=null;
try {
search = restHighLevelClient.search(request, RequestOptions.DEFAULT);
} catch (IOException e) {
e.printStackTrace();
}
List<Map<String,Object>> result=new ArrayList();
SearchHit[] hits = search.getHits().getHits();
//遍历结果,将高亮返回值title替换到原来的title中
for (SearchHit searchHit:hits){
Map<String, Object> sourceAsMap = searchHit.getSourceAsMap();
Map<String, HighlightField> highlightFields = searchHit.getHighlightFields();
HighlightField title = highlightFields.get("title");
if (title!=null){
StringBuilder highLightTitle=new StringBuilder();
Text[] texts = title.fragments();
for(Text text:texts){
highLightTitle.append(text);
}
sourceAsMap.put("title",highLightTitle);
}
result.add(sourceAsMap);
}
return result;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
继续访问
http://localhost:8080/search?keywords=Java&pageNum=1&pageSize=10,
通过断点可以看到,搜索的关键词已经被我们设置的span标签包住了。
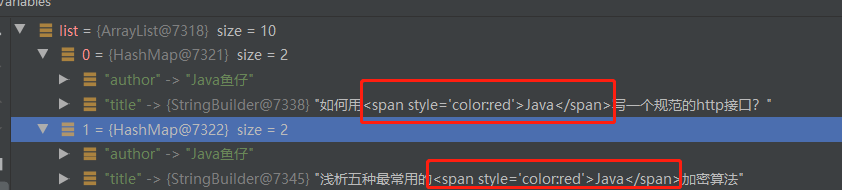
在前端thymeaf中,我是用了th:utext,这个标签可以将Html解析,最终的高亮显示如下:

# (六)总结
ES的应用到这里就结束了,ES可以很方便地嵌入到真实的项目中,对于应用来讲,了解到这一步已经足够,对于想要提高的人来说,还远远不够。作为最流行的分布式搜索引擎,ES还有许多值得学的地方,任重而道远。我是鱼仔,我们下期再见!