 平稳运行半年的系统宕机了,记录一次排错调优的全过程!
平稳运行半年的系统宕机了,记录一次排错调优的全过程!
作者:鱼仔
博客首页: codeease.top (opens new window)
公众号:神秘的鱼仔
# (一)前言
最近发生了一件很让人头疼的事情,已经上线半年且平稳运行半年系统在年后早高峰的使用时发生了濒临宕机的情况。访问速度特别慢,后台查到大量time_wait的连接,从代码层面到架构层面到网络层面排查了几天几夜,总算是有了结果。
# (二)架构、问题描述
先简单描述一下这个系统的架构,公网域名对应的公网IP连接着华为云的ELB弹性负载均衡服务,ELB下是两台Nginx服务器多活,Nginx下连接着四台内网应用集群服务器(通过专线),Mysql服务器读写分离、Redis服务器主从配置。
发生宕机问题时,四台集群服务器的Load Average飙到了200,要知道8核的服务器Load average超过40就需要注意了。同时Nginx的tcp连接数也异常,有大量的TIME_WAIT连接。

# (三)问题排查
这个问题主要原因还是系统挡不住突然间的高并发,根据上面的这些报错数据,首先是想办法把load average降下去。请求大于当前的处理能力,会出现等待,引起load average升高。因此主要从下面几个方面进行了排查:
# 3.1 检查Nginx配置
首先是运维人员检查Nginx配置,看看是否是配置不对造成大量time_wait连接,检查结果是没有问题。
# 3.2 抓网络请求
运维人员帮忙抓取了应用服务器在高并发时的网络包,最后分析下来有一个接口的请求次数是所有请求的40%。这是一个疑问点,这个请求为什么会被调用如此多的次数。
# 3.3 检查线程堆栈信息
因为请求数量如此多,因此需要检查占用CPU最高的线程堆栈信息,最后发现垃圾回收线程竟然占用了30%+资源,说明垃圾回收应该是存在一些问题的。

# 3.4 检查数据库连接池
检查数据库连接池是否正常,看看有无死锁或者资源耗尽等问题,查出来是一切正常的。
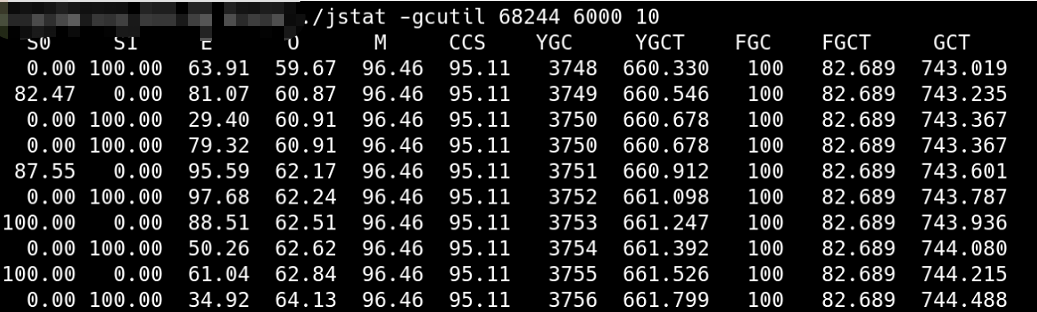
# 3.5 检查垃圾回收情况
通过jstat -gcutil 命令抓取垃圾回收情况,发现YGC很频繁,大概一秒一次,下图是高峰期过了之后的垃圾回收情况,YGC大概在一分钟8次左右。因此也是怀疑业务代码存在问题。
# (四)定位业务代码
通过上面的信息,我们初步怀疑那个被频繁调用的接口存在问题。查到代码后,发现每次刷新页面的时候,都会调用这个接口7次,这种调用太频繁了。同时代码中发现了大量JSON转换、序列化的情况,查了一些资料后发现这种行为确实会导致YGC频繁操作。
于是优化代码逻辑,刷新页面的时候调用一次接口就行,数据一次性传给前端,而不是多次调用。同时将没有必要的JSON转换代码优化掉。按理说现在的性能应该可以提升不少。打包、上传、重新观察。
# (五)问题还是存在
平稳了4天,在周五早晨高峰的时候,运行缓慢、负载高的情况又发生了。这下傻眼了,难道是有其他地方没有检查到吗。
这时想到一个问题,明明一直没有动这些服务器,为什么平稳运行了半年后突然出现问题,于是往其他方面去想,怀疑是从公网IP进来到应用服务器中的某条链路存在问题。于是尝试着断掉公网链路,去压测放在内网的这些应用,竟然不会出现之前的问题。
于是检查公网到内网的专线网络请求情况,发现出口带宽最高就只能到200M,就是早高峰的时候,而当时买的专线带宽是可以到500M的。因此怀疑是带宽满了导致请求进不来堵塞在公网的Nginx服务器上,而用户发现运行缓慢后频繁去刷新,导致大量的Tcp连接time_wait。于是赶紧联系相关服务商对网络带宽情况进行检测,果然500M的带宽直接打了折扣,联系相关人员处理这方面的问题。
同时一些静态资源放在私有云的服务器上也会导致网络流量大,将这些静态资源分离到公有云的Nginx服务器上,来降低这条专线的网络压力。
# (六)后续措施
后续观察来看,问题应该是解决了,当时发生宕机时,是用户反馈上来的,这一点很不合理,后续需要做好服务的监控等各项措施。同时在整体的排查问题时,也解决了一些虽然不是问题根源,但也需要优化的地方。
我是鱼仔,我们下期再见!