AI大模型部署指南
AI大模型部署指南
作者:鱼仔
博客首页: codeease.top (opens new window)
公众号:神秘的鱼仔
# 找模型
部署大模型的第一步是找模型,找模型推荐去魔塔社区: ModelScope 或者 huggingface ,这里基本包含了能用到的所有开源大模型,比如找一个glm-4v-9b模型
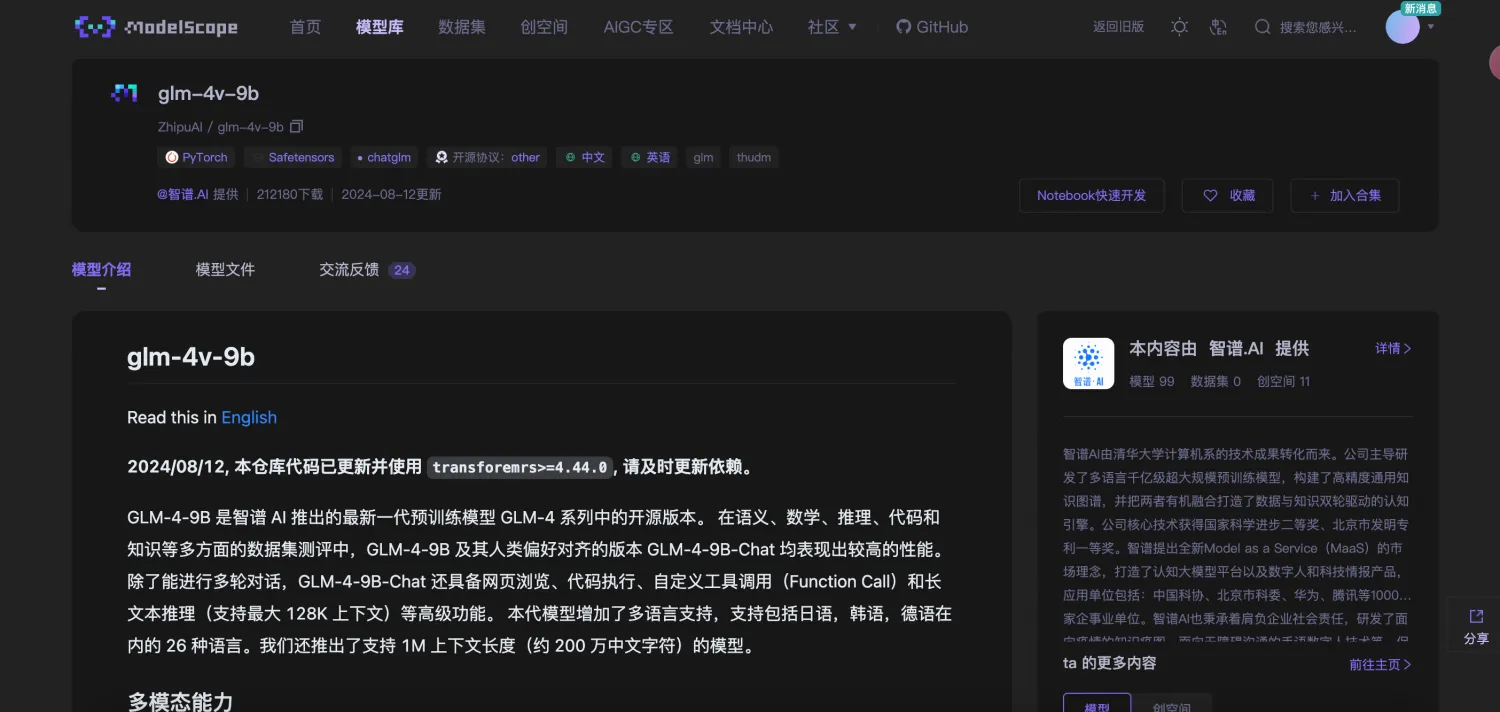
然后就可以看到模型介绍模块和模型文件模块,模型介绍里会有简单的将这个项目跑起来的案例,模型文件中包含了整个开源模型文件,会比较大。比如glm-4v-9b模型大小大约为28G
# 下载模型
模型下载有多种方式:SDK、Git、命令行
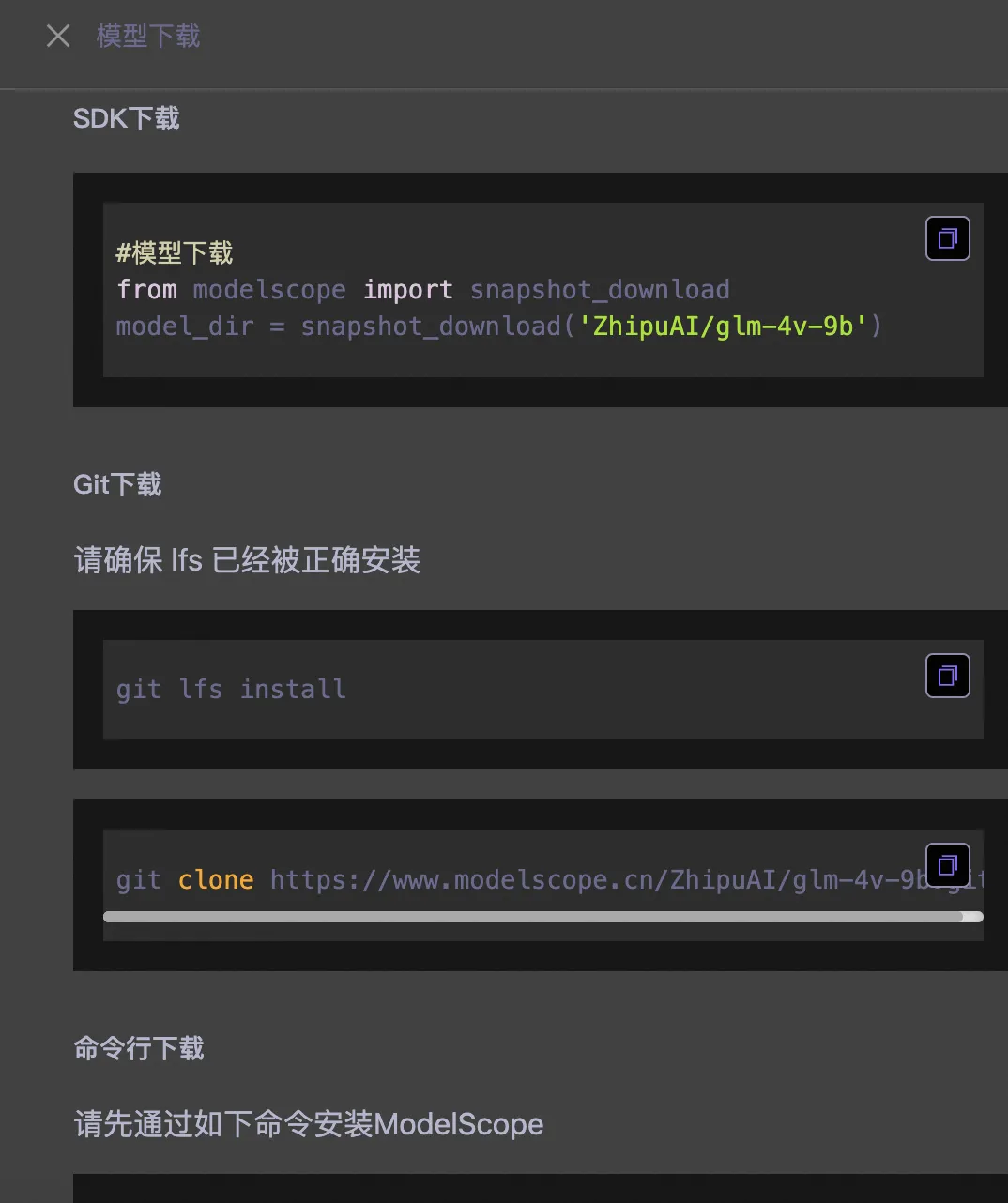
推荐使用SDK的下载方式(前提本地有Python环境),最稳定的下载方式
#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('ZhipuAI/glm-4v-9b')
2
3
模型下载完成后放到本地服务器即可。
# 安装服务器基础依赖
首先给服务器安装一些基础的包,这一步通过有root权限的用户安装
sudo yum update -y
sudo yum install -y gcc openssl-devel bzip2-devel libffi-devel zlib-devel readline-devel sqlite-devel
2
# 安装Python环境
不同的大模型对Python的版本都会有要求,目前一般都要求3.9以上,部分大模型已经要求3.10以上,按实际需求选择。生产服务器一般不会给你ROOT权限,因此下面的教程使用非Root权限账号即可,假设新建了一个用户叫做ai,所有的安装都在/home/ai下的目录。
因为现在很多模型要求openssl达到1.1.1以上版本,因此先安装openssl 1.1.1。
openssl1.1.1s 下载地址:https://openssl-library.org/source/old/1.1.1/index.html (opens new window)
安装:
tar -zxvf openssl-1.1.1s.tar.gz
cd openssl-1.1.1s
./config --prefix=/home/ai/bin/openssl
make
make install
2
3
4
5
# 安装 python3.9 环境
首先下载Python-3.9.19.tgz,下载地址:https://python.org/ftp/python/3.9.19 (opens new window)
下载完成后将文件放到Linux服务器上
tar -xvf Python-3.9.19.tgz
cd Python-3.9.19
make clean
export LD_LIBRARY_PATH=/home/ai/bin/openssl/lib:$LD_LIBRARY_PATH
./configure --prefix=/home/ai/bin/python3.9 --with-openssl=/home/ai/bin/openssl/lib
make
make altinstall
2
3
4
5
6
7
配置环境变量
vi ~/.bashrc
在最后一行加上:
export PATH=/home/ai/bin/python3.9/bin:$PATH
export LD_LIBRARY_PATH=/home/ai/bin/openssl/lib:$LD_LIBRARY_PATH
2
刷新环境变量
source ~/.bashrc
验证:
python3.9 --version
输出版本号即为成功
验证ssl
python3.9 -c "import ssl; print(ssl.OPENSSL_VERSION)"
输出1.1.1版本即为成功。
# 安装python3.10环境
首先下载Python-3.10.15.tgz,下载地址:https://python.org/ftp/python/3.10.15 (opens new window)
安装Python3.10.15
tar -xvf Python-3.10.15.tgz
cd Python-3.10.15
make clean
export LD_LIBRARY_PATH=/home/ai/bin/openssl/lib:$LD_LIBRARY_PATH
./configure --prefix=/home/ai/bin/python3.10 --with-openssl=/home/ai/bin/openssl/lib
make
make altinstall
2
3
4
5
6
7
配置环境变量
vi ~/.bashrc
在最后一行加上:
export PATH=/home/ai/bin/python3.10/bin:$PATH
export LD_LIBRARY_PATH=/home/ai/bin/openssl/lib:$LD_LIBRARY_PATH
2
刷新环境变量
source ~/.bashrc
验证:
python3.9 --version
输出版本号即为成功
证ssl
python3.10 -c "import ssl; print(ssl.OPENSSL_VERSION)"
输出1.1.1版本即为成功。
# 创建虚拟环境
进入到创建虚拟环境的目录,执行下面的命令创建虚拟环境
python3.9 -m venv lyenv
source lyenv/bin/activate
2
# 设置虚拟环境的pip源
假设你内网有一个PIP源,可以参考下面进行设置
pip config set global.index-url http://136.1.1.182:8081/repository/pypi/simple/
pip config set install.trusted-host 136.1.1.182
2
如果你是在公网访问,可以选择国内好用的源,以清华大学的源为例
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
# 如果需要设置可信主机(如使用HTTP协议的源),可以使用以下命令:
pip config set install.trusted-host pypi.tuna.tsinghua.edu.cn
2
3
# 安装PIP依赖
进入虚拟环境之后,需要先把运行大模型所需的依赖通过pip安装完成,版本请按照模型实际需要的来下载,下面这些只是案例
pip install vllm==0.6.1
pip install urllib3==1.26.6
pip install FlagEmbedding
pip install peft
pip install pydantic
pip install fastapi==0.114.1
pip install uvicorn==0.30.6
pip install transformers
2
3
4
5
6
7
8
# 启动大模型服务
将大模型跑起来有很多方式,官方一般会提供一段代码
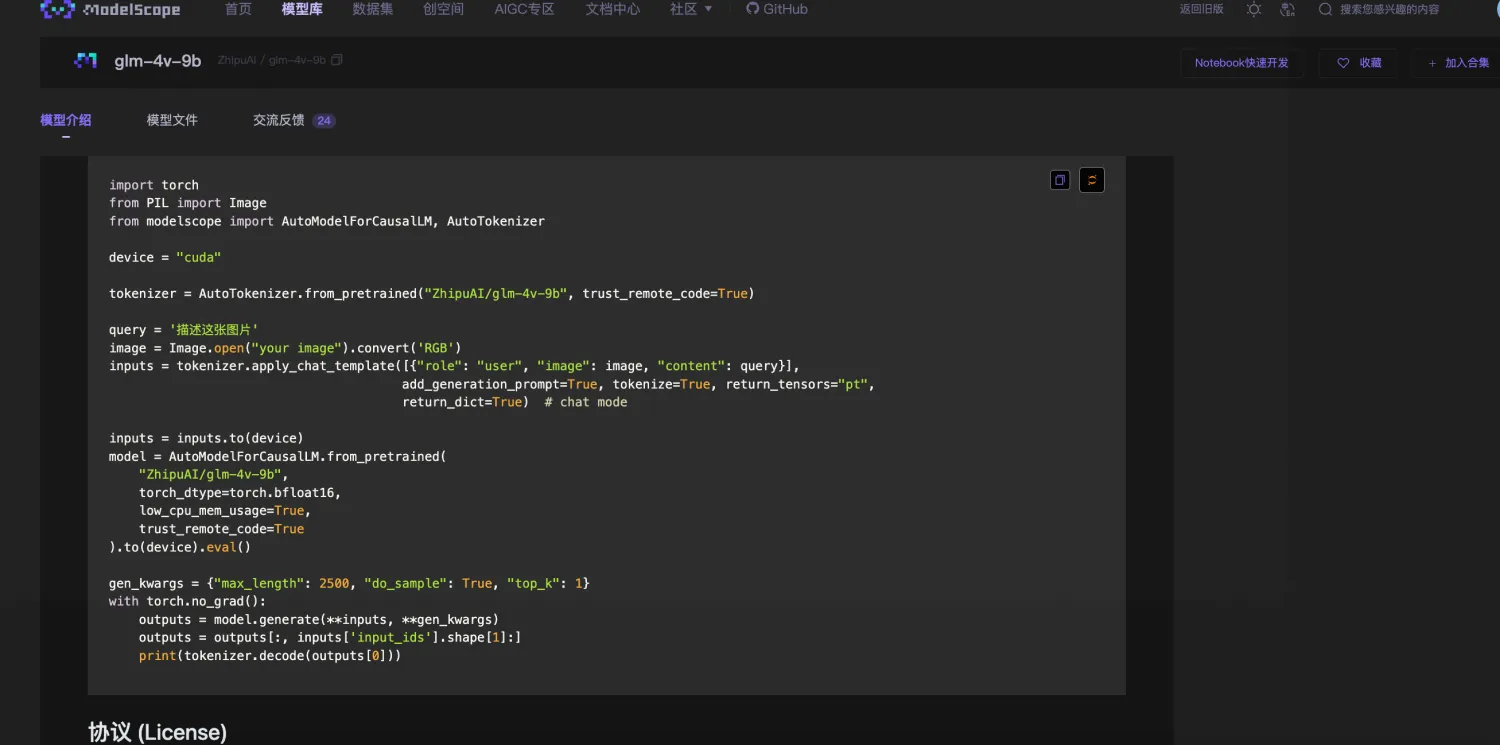
照着这个代码去跑,如果版本和官方要求完全一致,那一般是可以跑起来的,如果有个别包的版本不同,就需要不断踩坑去解决问题了。
采用一些框架去跑大模型,平常用的比较多的是ollama和vllm
设计理念
- Ollama:旨在简化在本地运行大型语言模型的过程,降低使用大型语言模型的门槛,使得开发者、研究人员和爱好者能够在本地环境快速实验、管理和部署最新的大型语言模型。
- vLLM:专注于提供高效的内存管理和推理加速,特别适用于资源受限的环境,如在低内存的设备上运行大型模型
应用场景
- Ollama:更适合在本地环境中快速部署和使用大型模型,如在个人电脑上,适合个人用户和研究人员进行模型实验和应用开发。
- vLLM:更适用于高并发、多检索点的复杂企业场景,在需要大量推理、并发任务处理以及复杂模型适配的场景中表现更为突出。
下面这几行是通过命令行的方式使用vllm启动大模型,大模型的路径就是我们最开始下载的那个大模型路径,分别介绍了使用单张卡和多张卡的启动方式,CUDA_VISIBLE_DEVICES代表GPU显卡的编号,通过nvidia-smi命令可以查看全部GPU的情况
nohup env CUDA_VISIBLE_DEVICES=1 vllm serve /home/ai/models/modelscope/hub/zhipu/glm-4-9b-chat-GPTQ-Int8 --port 10081 --trust-remote-code --served-model-name glm4_9b --quantization gptq >> /home/ai/projects/logs/10081.out &
CUDA_VISIBLE_DEVICES=2,3 nohup python -m vllm.entrypoints.openai.api_server --model=/home/ai/models/modelscope/hub/qwen/Qwen2.5-14B-Instruct --served-model-name=qwen_2_5 --device=cuda --port=10085 --host=0.0.0.0 --tensor-parallel-size=2 --dtype=auto --trust-remote-code --max-model-len=29690 >> /home/ai/projects/logs/10085.out &
2
3
# 解决问题
如果遇到一些常规的问题,比如依赖缺失等,网页上搜索即可。如果是和大模型相关的问题,用下面的方式会更容易解决。
因为大模型的更新很快,并且各个厂商都会发很多模型,会导致遇到问题通过搜索引擎可能搜不到,因此最好的解决方案的地方就是直接去github仓库的issues中去找
找不到就直接问,因为新模型发展期间会有专门的开发人员去解决问题,回复还是很快的
如果遇到一个自己解决了的Bug,还可以提个PR,在开源圈子里刷刷脸