 半个月了,DeepSeek为什么还是服务不可用
半个月了,DeepSeek为什么还是服务不可用
作者:鱼仔
博客首页: codeease.top (opens new window)
公众号:神秘的鱼仔
# 引言
1月22号的时候,我们发现市面上出现了一个很强的新AI模型 DeepSeek。于是在内网部署了它的14B蒸馏版本,这个模型一共占用了两张A10显卡共计42G显存,效果确实比其他14B模型要好很多。

在过年期间,DeepSeek忽然就爆了。引用一则数据
上线仅18天,DeepSeek应用便狂揽1600万次下载,并在25天内达到约4000万。相比之下,ChatGPT首次发布时的首月下载量为900万。截至1月31日,DeepSeek在苹果应用商店免费下载榜中,占据了157个国家/地区的第一名位置,包括美国市场。
上线仅20天,DeepSeek应用的日活用户数已突破2000万,达到2215万,超越字节跳动豆包的日活1695万。上线21天后,DeepSeek的月活用户数达到了3370万,使其在全球AI产品月活总榜上跻身第四。
但即使现在过去了半个月了,DeepSeek官方的问答网站依然是服务器繁忙,请稍后再试。另外一个比较有意思的点,每一天第一次访问都会给出结果,之后的访问就都不行了,推测官方应该是做了限流。
# 为什么迟迟无法访问
对于Java这类应用来说,别说半个月了,哪怕半天不可用都是P0事故了,但DeepSeek还真没办法很快解决问题。
上线二十天 DeepSeek 的日活用户突破2000万,这对于一家2023年成立的公司来说,根本没有足够的显卡去支撑这么庞大的调用量。以我部署的14B蒸馏模型为例:它的模型大小为29.59G,模型Tensor Tpye为BF16,光启动它占用的显存就达到了44G。
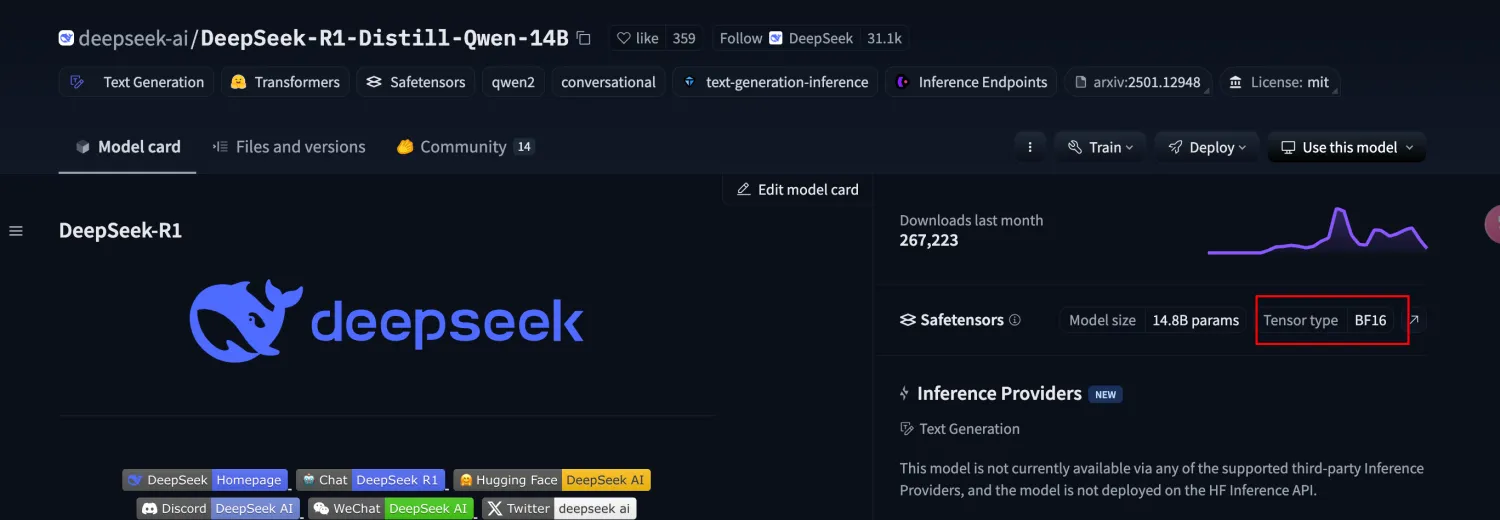
这里的Tensor Type表示 Tensor 的数据类型和存储格式,TensorType越大,需要占用的显存就越多,效果也会更好。
而DeepSeek所谓满血版的R1模型,它的参数已经达到了671B,模型文件大小已经达到700多G了。Tensor type使用的是一种混合类型,跑起来这个满血DeepSeek需要的显存加内存估计得达到1.3T左右。
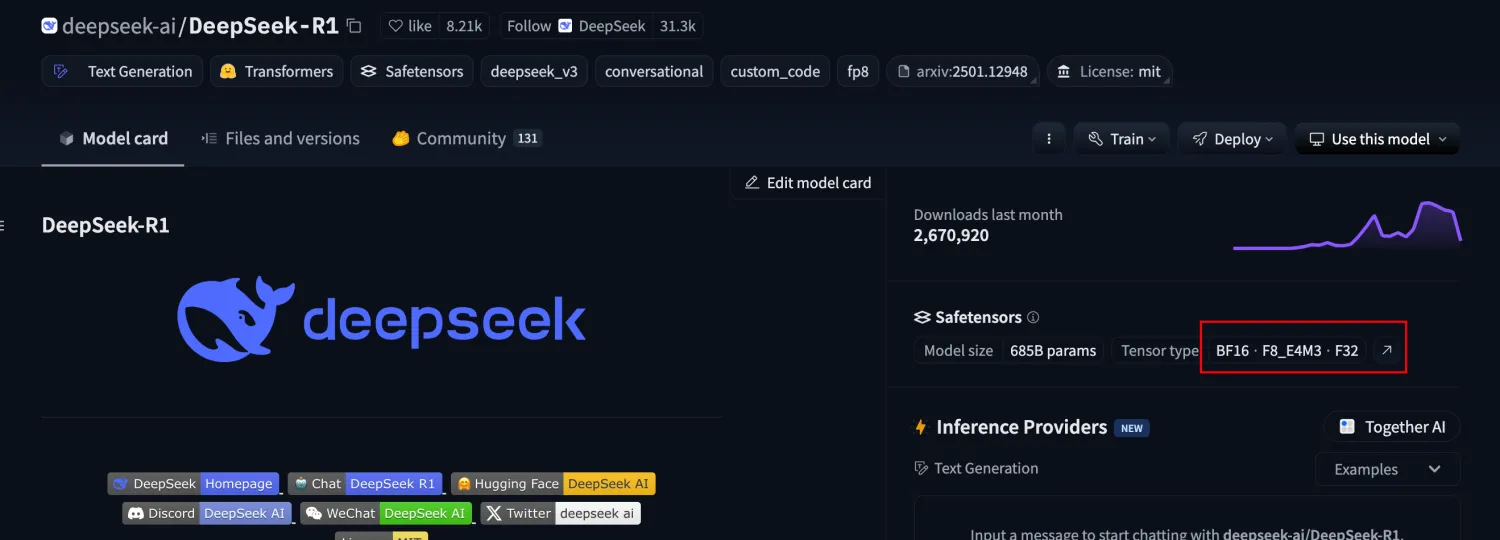
如果是把Tensor type量化为BF8,那也需要700多G的显存。通过这一组机器跑起来的大模型,能支撑的并发访问量也是有限的。因此如果想让DeepSeek官网畅快访问,唯一的解决办法就是不断加显卡,对于一家初创公司来说不可能自己花这么多钱去买,只能去依靠其他各个云服务厂商。
于是你就见到了DeepSeek的各路替代者,几乎每个有GPU储备的公司都开始抢占DeepSeek市场。对于DeepSeek来说,相当于分流了,也能在一定程度上减轻访问压力。目前流量最大的应该就是红衣教主的纳米AI搜索了。
但是作为爆款产品,它的流量依然十分庞大,所以即使过了半个月,依然一天只能用一次。
# 本地部署的误区
现在很多人说可以本地部署DeepSeek,有些还会提供收费课程教你如何本地部署。照着那些教程,你部署的大概率是蒸馏后的7B参数模型,因为它只需要占用十几个G的显存。甚至是1.5B的模型,只需要几个G的显存。
但这些和满血版671B参数的模型差距十分大。对普通人来说,如果官网的服务不可用,去使用中大厂提供的DeepSeek服务就可以了。现在几乎所有云厂商都接入了DeepSeek。
# DeepSeek的破局方式
目前来看DeepSeek最主要的问题是无法承载高调用量的压力,最直接的办法就是招人,买机器。目前DeepSeek还是有在招这方面人才的。
第二种方案是背靠一家能提供云服务器硬件的大厂,以某种合作的方式进行,这样可以省去服务器和运维上的很多麻烦。
当然还有一种说法,有人认为现在DeepSeek遍地开花的情况就是他的创始人想要看到的画面,具体如何就看时间给出答案了。